When M.D. is a Machine Doctor – Dr. Eric Topol, Ground Truths
Helping medical doctors and patients in the Foundation Model A.I. era
FOR EDUCATIONAL PURPOSES
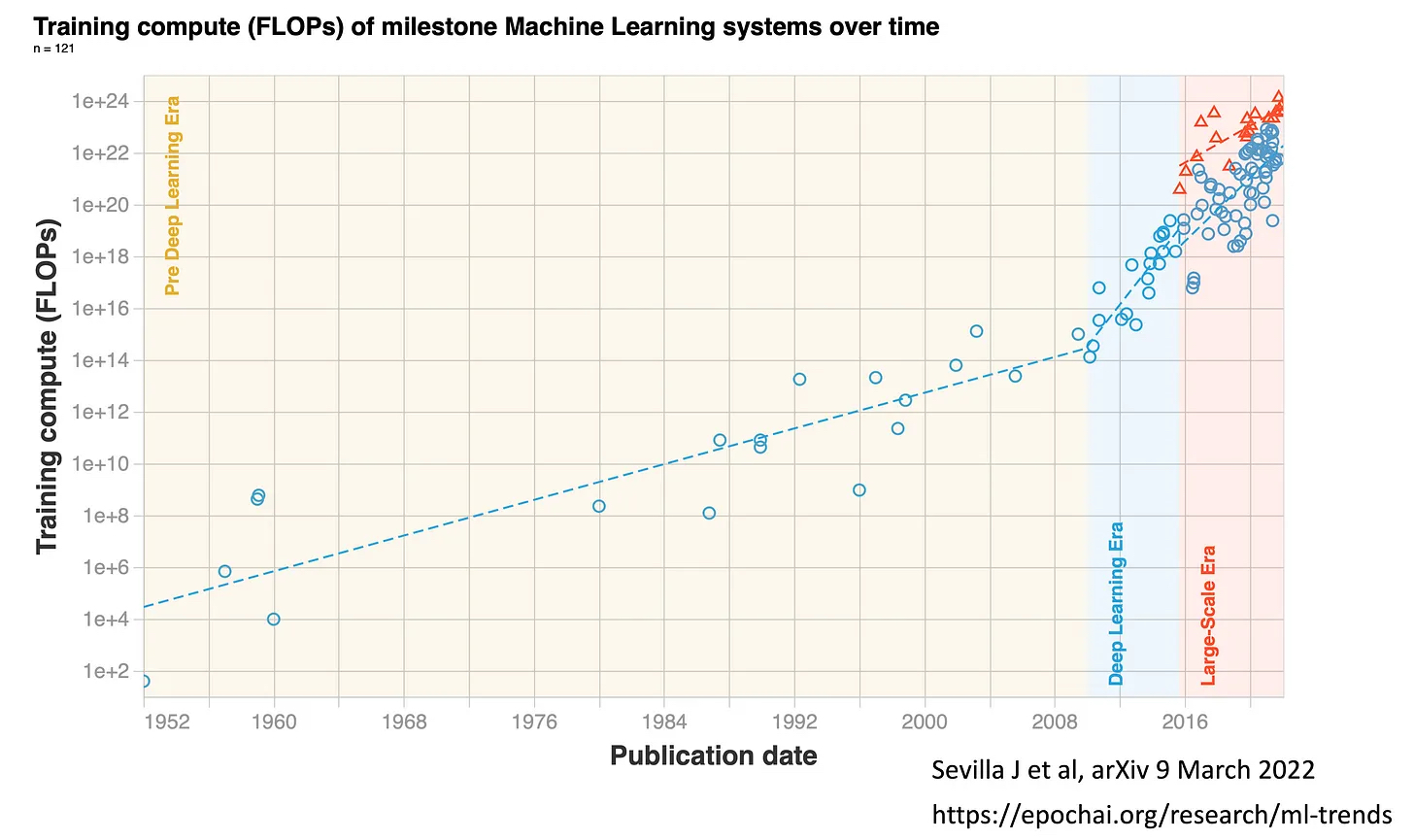
“Back in 2019, I wrote Deep Medicine, a book centered on the role that deep learning will have on transforming medicine, which until now has largely been circumscribed to automated interpretation of medical images. Now, four years later, the AI world has charged ahead with large language models (LLMs), dubbed “foundation models” by Stanford HAI’s Percy Liang and colleagues (a 219-page preprint, the longest I have ever seen), which includes BERT, DALL-E, GPT-3, LaMDA and a blitz of others, also known by others as generative AI. You can quickly get an appreciation of the “Large-Scale Era” of transformer models from this Figure below by Jaime Sevilla and colleagues. It got started around 2016, with unprecedented levels of computer performance as quantified by floating-point operations per second (FLOPs). Whereas Moore’s Law for nearly 6 decades was characterized by doubling of training computation every 18-24 months, that is now doubling every 6 months in the era of foundation models. As of 2022, the training computation used has culminated with Google’s PaLM with 2.5 billion petaFLOPs and Minerva with 2.7 billion peta FLOPS. PaLM uses 540 billion parameters, the coefficient applied to the different calculations within the program. BERT, which was created in 2018, had “only” 110 million parameters, which gives you a sense of exponential growth, well seen by the log-plot below . In 2023, there are models that are 10,000 times larger, with over a trillion parameters and a British company Graphcore that aspires to build one that runs more than 500 trillion parameters.”
Learn More:
-
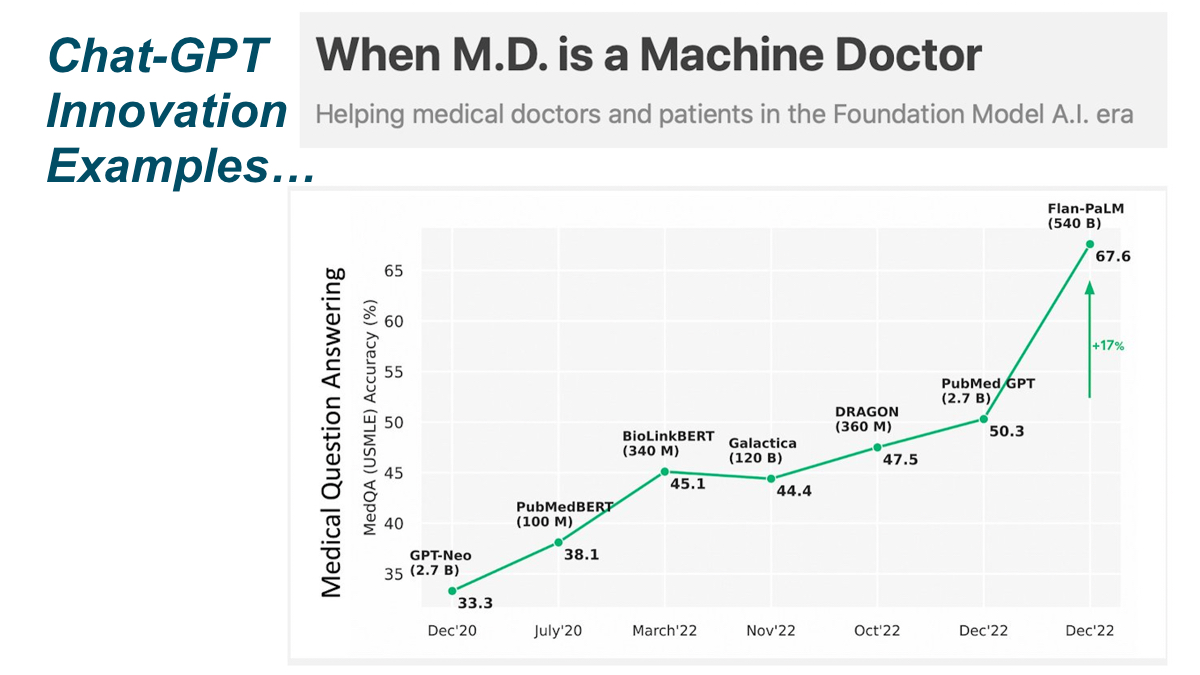
Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models – PLOS Digital Health
-
Abstract. We evaluated the performance of a large language model called ChatGPT on the United States Medical Licensing Exam (USMLE), which consists of three exams: Step 1, Step 2CK, and Step 3. ChatGPT performed at or near the passing threshold for all three exams without any specialized training or reinforcement. Additionally, ChatGPT demonstrated a high level of concordance and insight in its explanations. These results suggest that large language models may have the potential to assist with medical education, and potentially, clinical decision-making.